
ICETOOL SPLICE Operator
Advertisement
SPLICE operator joins the records together from the multiple files based on the coded fields with matching values. It uses the join fields from different input records to create an output record with information from two or more records.
Syntax -
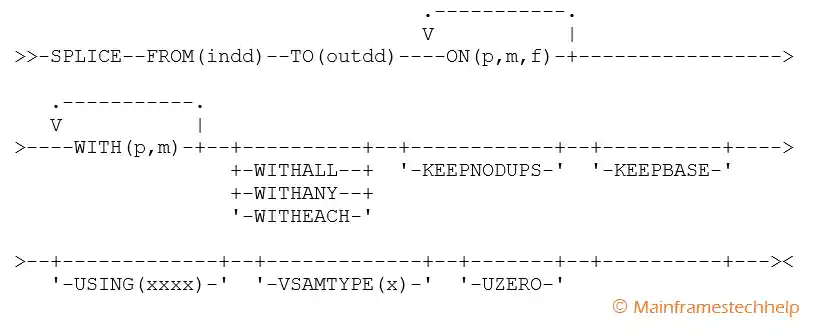
Required Operands
- FROM - specifies ddname of the input file. It is mandatory when FROM operand is coded.
- TO - specifies 1 to 10 ddnames of output files. TO and USING operands can code at the same time.
- ON (p,l,f) - specifies the field(s) used for validation.
- p - gives the starting position of field.
- l - gives the length of the field. The field should not be beyond position 32752 or the end of the record.
- f - gives the format of the data. The valid formats are PD(Signed Packed decimal - 1 to 16 bytes) and ZD (Signed Zoned decimal - 1 to 31 bytes).
Optional Operands
- VSAMTYPE - specifies the record format for a VSAM input file. It should be either F (fixed-length) or V (variable-length) record processing.
- WITHALL - used to splice the first duplicate with all the WITH fields from the second and subsequent duplicates.
- WITHANY - used to splice the first duplicate with nonblank WITH fields from the second and subsequent duplicates.
- WITHEACH - used to splice the first duplicate with one WITH field from the second and subsequent duplicates. By default, non-matching records are not kept.
- KEEPNODUPS - used to keep non-matching records. By default, the base record is not kept.
- KEEPBASE - used to keep the base record.
- UZERO - Causes -0 to be treated as unsigned, that is, as 0.
- USING - specifies the first 4-characters of the ddname (xxxxCNTL) for the DFSORT control statement. XXXX name is the user-defined name. Either TO, USING, or both operands can code at the same time.
Example -
Scenario - Create one spliced record for each match in two files.
In this example, we are joining employee details with employee salary based on employee number(columns 1-3).
INPUT1 - MATEPK.INPUT.PSFILE
----+----1----+----2----+----3----+----4----+----5----+----6----+----7----+----8
001 PAWAN MAINFRAME JPM AP IN
002 SRINIVAS TESTING ORACLE TG IN
003 SRIDHAR SAS CG OR US
004 VENKATESH ABAP CSC CA IN
005 RAVI HADOOP CTS FL US
006 PRASAD HR INFOSYS MI US
007 RAJA TESTING IBM CA USINPUT2 - MATEPK.INPUT.PSFILE3
----+----1----+----2----+----3----+----4----+----5----+----6----+----7----+----8
001 0000100000
002 0000095000
003 0000080000
004 0000053000
005 0000072000
006 0000066000
007 0000047000JCL -
----+----1----+----2----+----3----+----4----+----5----+
...
//STEP01 EXEC PGM=ICETOOL
//INDD1 DD DSN=MATEPK.INPUT.PSFILE,DISP=SHR
//INDD2 DD DSN=MATEPK.INPUT.PSFILE3,DISP=SHR
//TEMP DD DSN=&&TEMP,DISP=(MOD,PASS),
// SPACE=(TRK,(5,5)),UNIT=SYSDA,
// DCB=(DSORG=PS,RECFM=FB,LRECL=80,BLKSIZE=800)
//OUTDD DD DSN=MATEPK.OUTPUT.PSFILESP,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=DEVHD4,
// SPACE=(TRK,(1,1),RLSE),UNIT=SYSDA,
// DCB=(DSORG=PS,RECFM=FB,LRECL=80,BLKSIZE=800)
//TOOLIN DD *
COPY FROM(INDD1) TO(TEMP) USING(CTL1)
COPY FROM(INDD2) TO(TEMP) USING(CTL2)
SPLICE FROM(TEMP) TO(OUTDD) ON(1,3,ZD) WITH(70,10)
/*
//CTL1CNTL DD *
OUTREC FIELDS=(1,69,70:X)
/*
//CTL2CNTL DD *
OUTREC FIELDS=(1:1,3,70:10,10)
/*
...OUTPUT - MATEPK.OUTPUT.PSFILE
----+----1----+----2----+----3----+----4----+----5----+----6----+----7----+----8
001 PAWAN MAINFRAME JPM AP IN 0000100000
002 SRINIVAS TESTING ORACLE TG IN 0000095000
003 SRIDHAR SAS CG OR US 0000080000
004 VENKATESH ABAP CSC CA IN 0000053000
005 RAVI HADOOP CTS FL US 0000072000
006 PRASAD HR INFOSYS MI US 0000066000
007 RAJA TESTING IBM CA US 0000047000Advertisement