VSAM Components
A component is an individual part of a VSAM dataset. Each component has an entry, a name in the catalog, and an entry in the VTOC. A component can be multi-extent and multi-volume.
VSAM dataset has three components, and those are -
- Cluster
- Data component
- Index component
Cluster -
A cluster is a logical definition for a VSAM dataset and has the below one or two components -
- The data component.
- The index component.
A VSAM cluster is a logical definition for the VSAM dataset of any type (ESDS, KSDS, RRDS, or LDS).
IDCAMS DEFINE CLUSTER access-method services used to define VSAM datasets (clusters) with data and index components. This process includes creating an entry in an integrated catalog without any data transfer.
The below information is mandatory to create the dataset -
- Name of the dataset.
- Name of the catalog to contain this definition.
- Organization (sequential, indexed, or relative).
- Device and volumes that the dataset occupy.
- Space required for the dataset.
- Record size and control interval sizes (CISIZE).
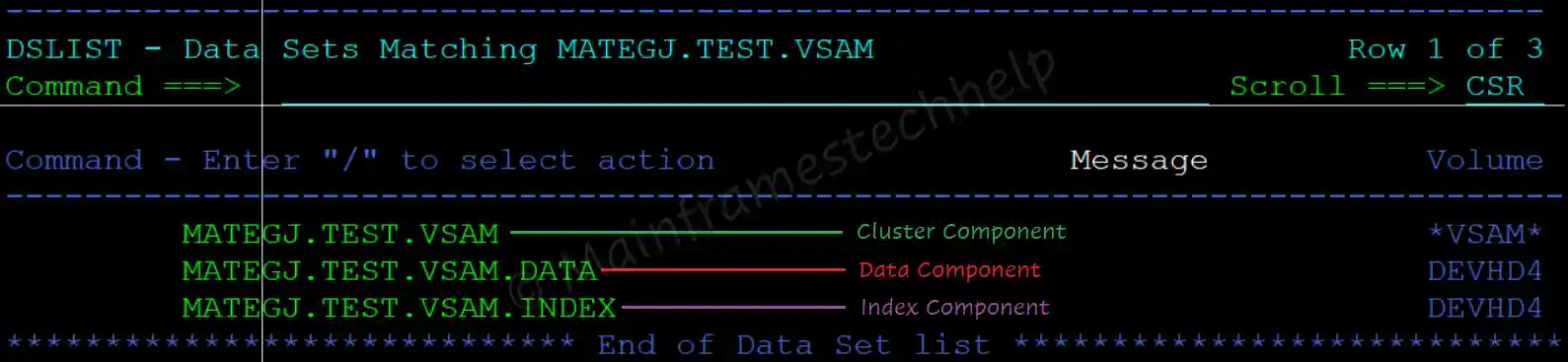
For example - Assume MATEGJ.TEST.VSAM is the VSAM KSDS file created.
MATEGJ.TEST.VSAM - Cluster Component Data Component -
- VSAM Data Component contains data records. These data records can be small or large that might spread across CIs and CA.
- Every VSAM file type (ESDS, KSDS, RRDS, VRRDS, LDS) has a data component. KSDS and vRRDS only have the index component.
- The data component is part of the VSAM dataset, alternate index, or catalog.
For example - Assume MATEGJ.TEST.VSAM is the VSAM KSDS file created.
MATEGJ.TEST.VSAM
MATEGJ.TEST.VSAM.DATA - Data ComponentIndex Component -
- The index component contains index records with the key fields/RBA of data records.
- The key fields are a collection of the single or multiple fields from the logical data record.
- VSAM can randomly retrieve the record from the data component using the index.
For example - Assume MATEGJ.TEST.VSAM is the VSAM KSDS file created.
MATEGJ.TEST.VSAM - Cluster Component
MATEGJ.TEST.VSAM.DATA - Data Component
MATEGJ.TEST.VSAM.INDEX - Index Component