
VSAM Basic Concepts and Terminology
While developing VSAM, the designing team defined some basic important concepts and terms. Before learning more about VSAM, knowing about these concepts and terms will be helpful. Those are -
- Clusters
- Components
- Logical Record
- Physical Record
- Control Interval
- Control Area
- Spanned Records
- Alternate Indexes
- Sphere
- Splits
Cluster -
A VSAM cluster is a logical definition for a VSAM dataset and has the below one or two components -
- The data component contains the data records.
- The index component of the key-sequenced cluster consists of the index records.
A VSAM cluster is a logical definition for the VSAM dataset of any type (ESDS, KSDS, RRDS, or LDS).
IDCAMS DEFINE CLUSTER access-method services used to define VSAM datasets (clusters) with data and index components. This process includes creating an entry in an integrated catalog without any data transfer.
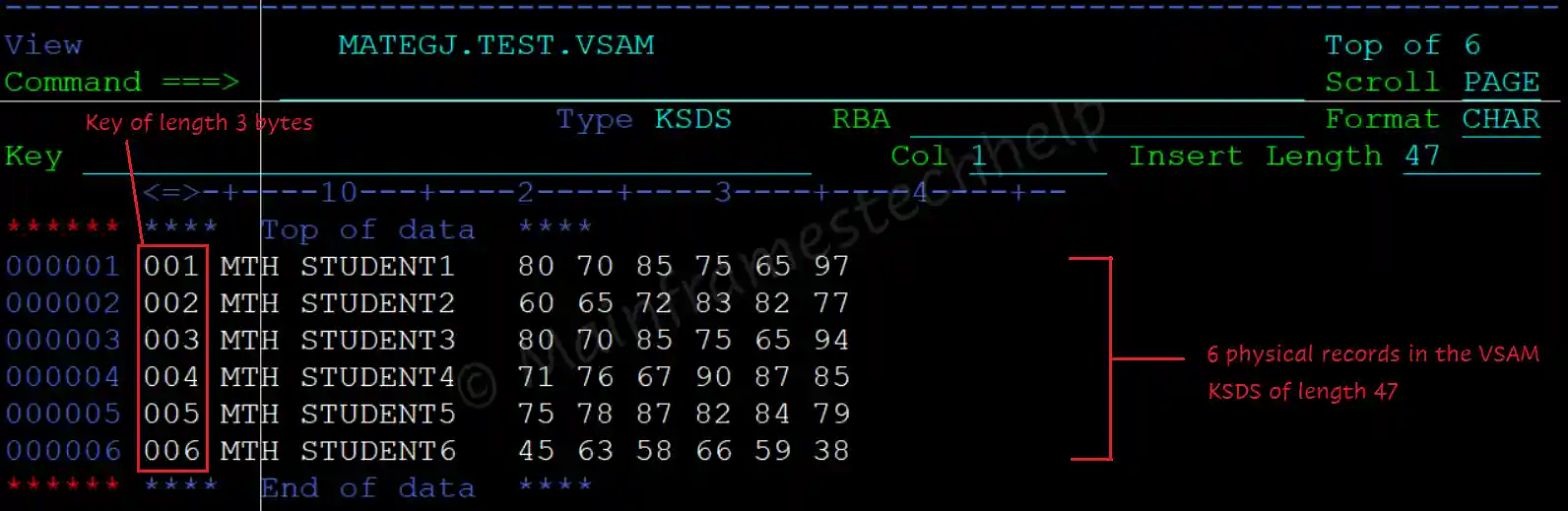
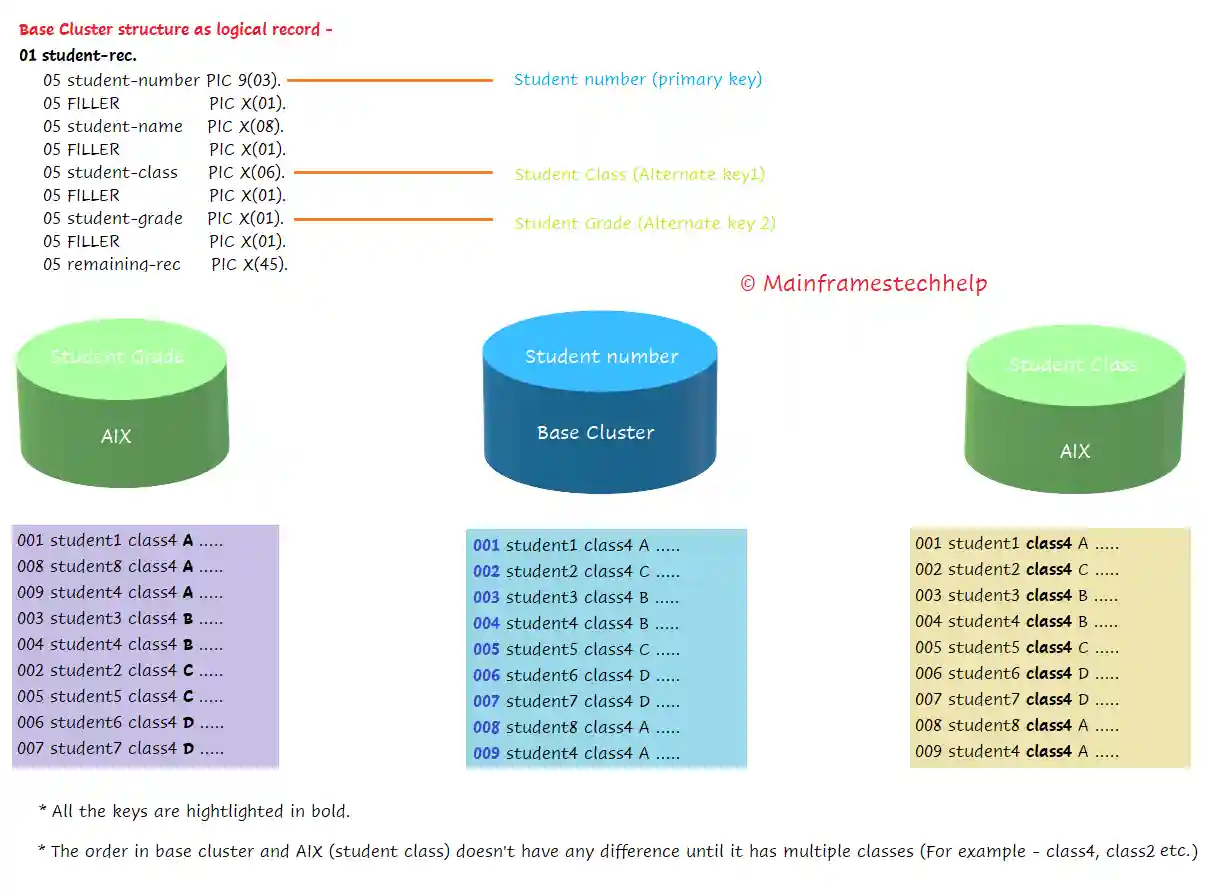
For example - Assume MATEGJ.TEST.VSAM is the VSAM KSDS file created.
MATEGJ.TEST.VSAM - Cluster Component
MATEGJ.TEST.VSAM.DATA - Data Component
MATEGJ.TEST.VSAM.INDEX - Index ComponentLogical record -
- A logical record is a logical representation of a record used to populate the data to VSAM or map the data while retrieving it from VSAM.
- The application program uses logical records to access and process the data through I/O operations from the dataset.
- The application programmer designs the logical records and it is a set of fields (that includes key fields) with logical descriptions.
- A logical record can be of a fixed-length or a variable-length, and VSAM supports both type of records based on the file organization type (file type).
For Example - A VSAM KSDS file with 47 bytes length logical record defintion as follows -
DATA DIVISION.
FILE SECTION.
FD KSDS-1.
RECORD CONTAINS 47 CHARACTERS.
BLOCK CONTAINS 470 CHARACTERS.
DATA RECORD is KSDS-RECORD-1.
RECORDING MODE IS F.
01 KSDS-RECORD-1.
05 KSDS-KEY PIC X(03).
05 KSDS-DATA PIC X(44).
In the above example, KSDS-RECORD-1 is the logical record used to process the physical VSAM file.
Ways to identify logical records -
VSAM has these ways to identify logical records -
- Key field - Key field is an important and unique field. Its contents are used to identify the logical record.
- Relative byte address (RBA) - RBA is an offset of logical record first byte. For example - Assume if the first logical record RBA is zero, then the second logical record RBA is the length of the first record. Similarly, the third record RBA is the length of the first two records, and so on.
- Relative record number (RRN) - RRN is the relative number of the logical record. For example - RRN is 2, which means it is the third record in the dataset.
Physical record -
- A physical record is an actual record that is stored on the disk allocated for the file.
- A physical record may be a set of one or more logical records.
- A physical record is also called a physical block or simply a block.
For example -
Control Interval -
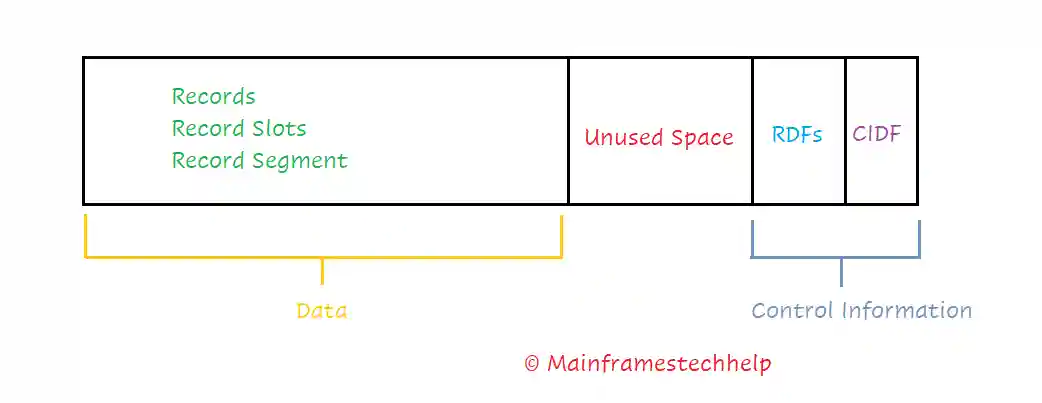
- Control interval (CI) is the fundamental block of every VSAM dataset.
- A CI is the contiguous memory area of DASD(Direct Access Storage Device) used to store the physical records and control information about the records.
- A CI is a set of physical blocks that are read or written during the I/O operation.
- The CI size can be from 512 bytes to 32 KB.
- The CIs size can vary from one dataset to another dataset. However, all the CIs within the data component of a cluster should have the same length.
- The physical record(block) size is decided by VSAM based on CI size. For better benefits, use 3390 tracks for the size of the physical record.
- Small CI is suitable for random access because small CI avoids bringing unnecessary logical records copying to memory.
- Large CI is suitable for sequential access because large CI gets more records in a single read, indirectly reducing the number of reads.
The CI components impact the CI size decision are -
- No. of logical records are stored in CI.
- Free space for records insertion.
- Control information - Control information is a combination of two fields -
- Control Interval Definition Field (CIDF) - CI has only one CIDF. It is a 4-byte field and contains information about the location and amount of free space in the CI.
- Record Definition Fields (RDFs) - CI can have several RDFs. It is a 3-byte field and describes about the record length. For fixed-length records, there are two RDFs, one with the fixed-length size and the other with the number of records with that length. For the variable-length record, there is one RDF for each logical record.
The CI components and properties can vary depending on the dataset type. For example, a VSAM LDS does not have CIDFs and RDFs in its CI.
CI size can be decided in three ways -
- User-defined size by specifying in AMS DEFINE command.
- VSAM determined.
- The administrator-defined CISIZE.
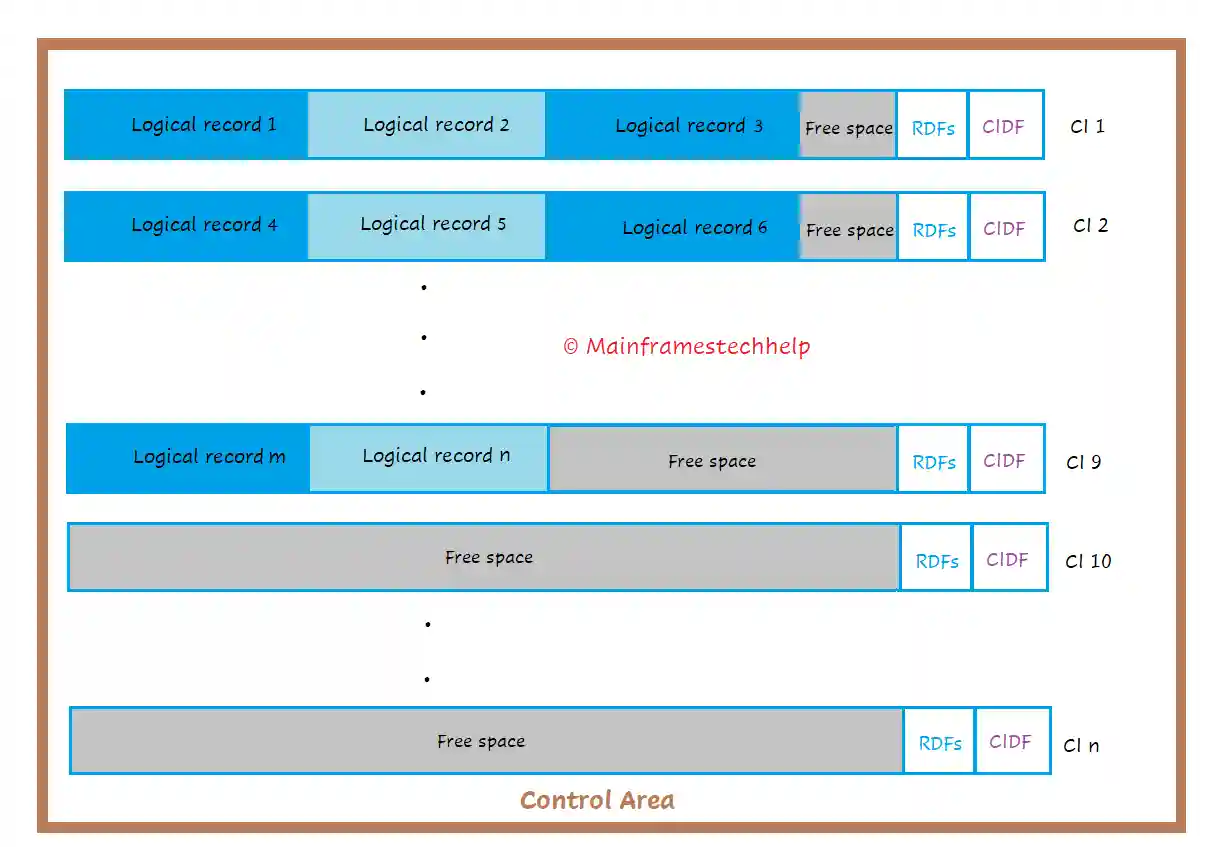
Control Area -
- Control Area (CA) is a unique concept to VSAM.
- A Control Area (CA) is a fixed-length contiguous memory area of DASD formed by two or more Control Intervals (CIs).
- Generally, CA's maximum size is one cylinder, and the minimum size is one track.
- The CA size is defined during the dataset definition.
- A VSAM dataset is mostly created on multiple Control Areas (CAs).
- VSAM datasets are always extended in the units of CAs (i.e., multiples of CAs).
- Spanned record maximum size is one CA.
- In a sequential process, a single I/O operation won't cross CA's boundaries.
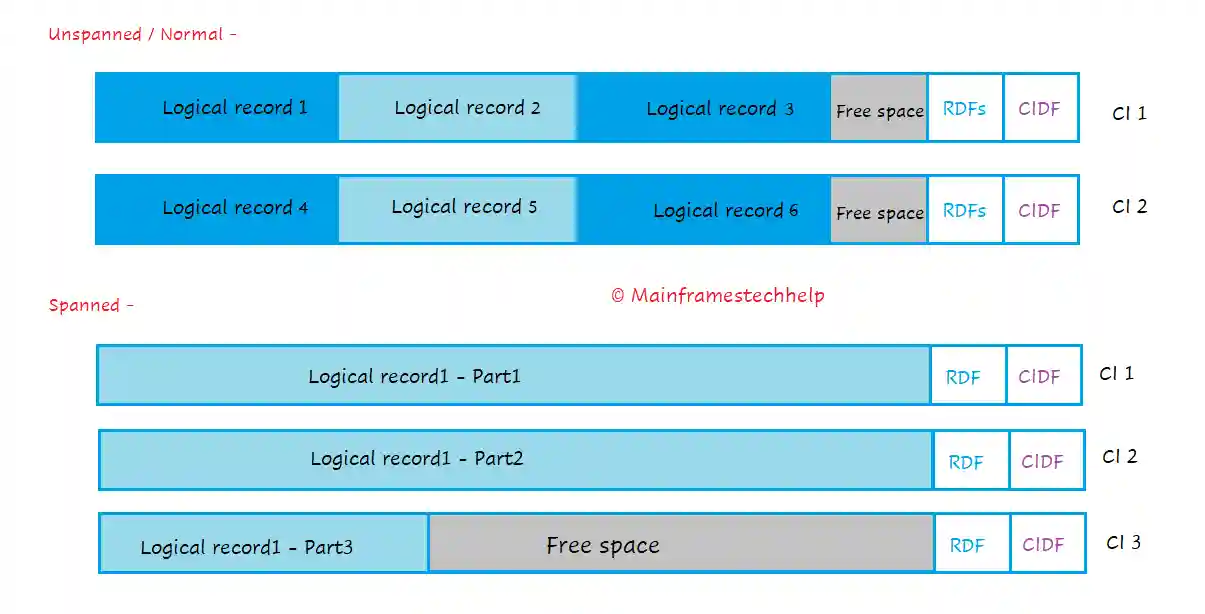
Spanned Records -
- Spanned records are larger logical records than the CI size.
- DEFINE CLUSTER should use SPANNED attribute to have spanned records when defining the dataset. Spanned records can store on multiple control intervals (CIs).
- RDFs can specify whether the record is spanned record or not.
- Spanned records are needed when the application program uses long logical records.
- A spanned record can use in the data component of the Alternate Index (AIX) cluster.
- If the spanned records are used for KSDS, the primary key should be within the first CI.
Notes -
- A spanned record always begins on a control interval (CI) boundary and fills one or more CIs within a single CA.
- A spanned record can't share the CI with any other records.
- CIs free space at the end of the spanned record is not filled with other records.
- The CIs free space at the end of the spanned record is used only to extend the spanned record.
- The maximum size of the spanned record is the size of the control area (CA).
Alternate Indexes -
- Alternate indexes (AIXs) allow access to the logical records sequentially or directly using alternate key fields (other than the primary key field).
- Each alternate index is a KSDS cluster with an index and data components.
- AIX eliminates the requirement of storing the same data in a different order for different applications.
- The AIX data component contains a set of primary keys that are associated with the alternate key.
- IDCAMS utility is used to define and create AIX.
- AIX can define and used in three steps, and those are -
- Create AIX - Defines alternate index (IDCAMS DEFINE command).
- Build AIX - Creates an alternate index (IDCAMS BLDINDEX command).
- Define Path - Defines the mapping between primary and alternate keys to access the records faster (IDCAMS DEFINE PATH).
For example -
Notes -
- Any key except the primary key in the base cluster can use as an alternate key.
- An alternate key can overlaps any other key (primary in KSDS or any other alternate key).
- The alternate key can have duplicate values.
- An alternate key value can have more than one primary key value. For example - the primary key is the student number, and the alternative key is class. i.e., A class has several students.
- The AIX cluster data component contains the alternate key value (pointers to the data component in a base cluster) and all its corresponding primary keys.
- The primary keys are in ascending order within the alternate index value. The alternate index is also in ascending order.
- If an alternate key has many primary keys, consider the AIX as spanned and compressed.
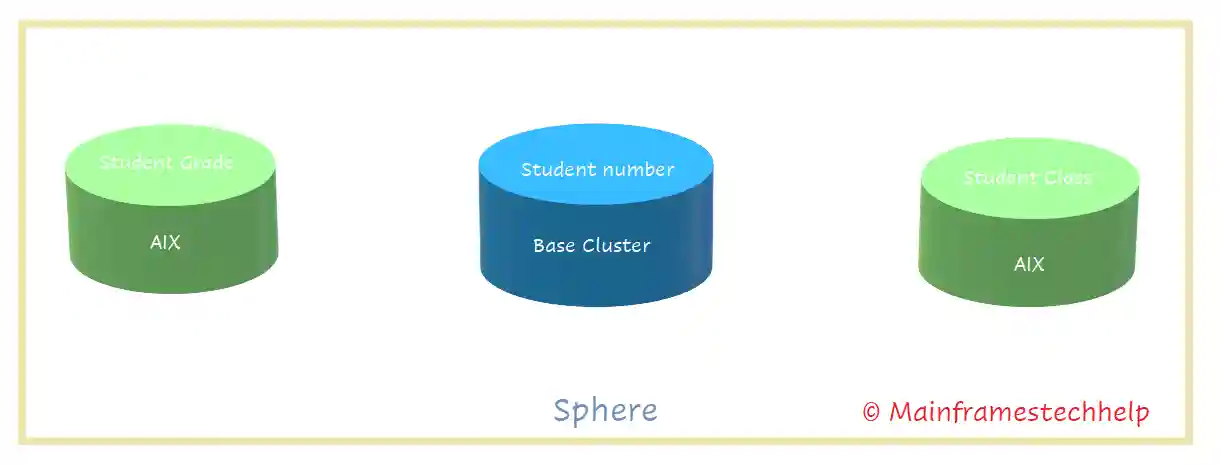
Sphere -
- A sphere is a group of base clusters and their associated clusters (AIX).
- The associated clusters are the base cluster's alternate indexes (AIX). i.e., base cluster plus all its AIXs.
Splits -
CI split occurs when there is not enough space to process the below two requests -
- Inserting a new record at the end of CI.
- An existing record length expanded.
If any CI is free in the same CA, approximately half of the records from fully loaded CI move to other free CI. In the CI split, both CIs belongs to the same CA.

Similarly, if there is not enough space in all the CIs of a CA, then CA is split occurs. Approximately half of the CIs of fully loaded CA data move to the other free CIs of different CA.

The split worsens the performance. However, the following split decreases the probability of having another one.
CI and CA split occur in KSDS and VRRDS datasets.