
IMS DB Secondary Index
Secondary indexing allows for the retrieval of data segments based on non-primary key fields, known as secondary keys. This mechanism is particularly useful when:
- You need to access data using fields that are not part of the primary key.
- You want to improve performance for specific query patterns.
- You require alternative access paths to the data.
By creating secondary indexes, IMS facilitates direct access to segments using these secondary keys, enhancing flexibility and efficiency in data retrieval.
Example Scenario:
Consider a company that manages multiple projects, each with several employees. The IMS database hierarchy might be structured as follows:
- Root Segment: COMPANY
- Child Segment: PROJECT
- Child Segment: EMPLOYEE
- Child Segment: PROJECT
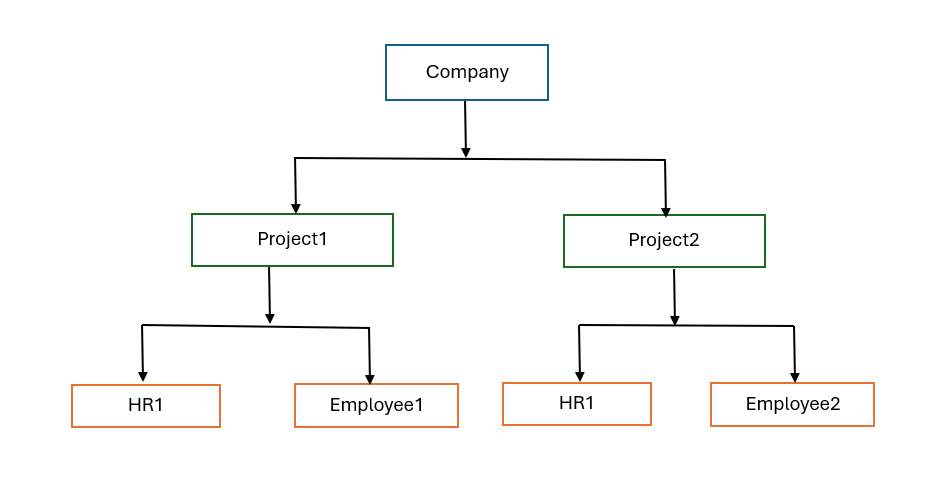
In this structure:
- The primary key to access an EMPLOYEE segment would be a concatenation of COMPANY ID, PROJECT ID, and EMPLOYEE ID.
- If you want to retrieve all projects an employee is working on, you'd need to traverse from the COMPANY to each PROJECT and then to EMPLOYEE, checking for the employee's ID.
This approach can be inefficient, especially in large databases. Secondary indexing can help by allowing direct access to EMPLOYEE segments based on EMPLOYEE ID, bypassing the need to traverse the entire hierarchy.
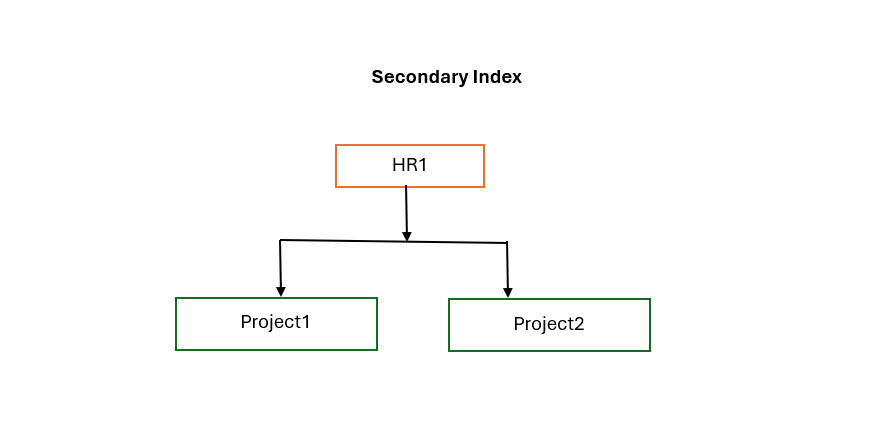
Components of a Secondary Index:
A secondary index in IMS consists of index pointer segments stored in a separate database. Each index pointer segment comprises two main elements:
- Prefix Element: Contains a pointer to the index target segment—the actual data segment in the primary database that you want to access.
- Data Element: Holds the value of the secondary key from the index source segment—the segment from which the secondary index is derived.
It's important to note that the index source segment and the index target segment can be different. When a secondary index is established, IMS automatically maintains it, ensuring consistency and integrity. However, creating multiple secondary indexes can introduce additional processing overhead, so they should be created with caution.
Implementing Secondary Indexing
To implement secondary indexing in IMS:
- Define the Secondary Index Database (DBD): This involves creating a separate DBD for the index database, specifying the structure of the pointer segments.
- Update the Primary Database DBD: Add LCHILD and XDFLD statements to define the relationship between the primary database and the secondary index.
- Generate the DBDs: Use the DBDGEN utility to generate the DBDs for both the primary and index databases.
- Update the PSB (Program Specification Block): Specify the secondary index database in the PSB to allow application programs to use the index.
Secondary Data Structures
Implementing a secondary index alters the apparent hierarchical structure of the database from the perspective of application programs. This new structure is referred to as a secondary data structure. Key points include:
- The index target segment becomes the apparent root segment in the secondary data structure, even if it's not the root in the primary database.
- This rearrangement does not modify the physical structure of the database on disk; it's a logical view presented to the application.
Sparse Sequencing
Sparse sequencing, also known as sparse indexing, is a technique used to optimize the performance of secondary indexes by selectively including index source segments. Key aspects include:
- Segments can be excluded from the secondary index based on specific criteria.
- IMS uses suppression values or suppression routines (user-defined programs) to determine whether a segment should be indexed.
- If a segment's sequence field matches a suppression value, no index relationship is established for that segment.
- This selective indexing reduces the size and maintenance overhead of the secondary index, improving overall performance.
Sparse sequencing allows for more efficient secondary indexes by focusing on the most relevant data segments.