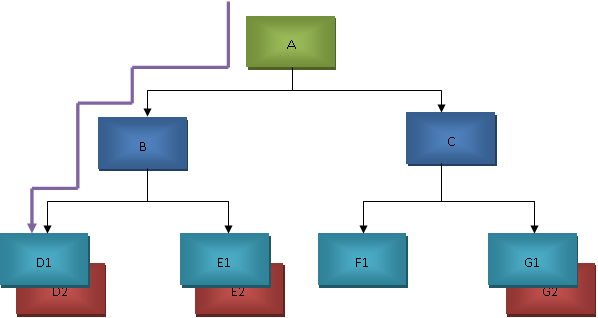
IMS DB Database Path
A database path refers to the sequence of segments that starts from the root segment and leads to a specific dependent segment. This path represents the hierarchical relationship between segments and is crucial for data retrieval and manipulation.
Example:
- Company Segment (Parent)
- Project Segment (Child)
- Employee Segment (Child)
- Project Segment (Child)
To access an employee's data, IMS traverses this path: Company → Project → Employee.
Navigating the Database Path
IMS follows a top-down, left-to-right navigation method:
- It starts at the Company segment.
- Moves into the first Project under that company.
- Then continues to the first Employee under that project.
- Only after that, it checks for additional employees under the same project, or moves on to the next project.
Example:
If "TechCorp" has two projects — "AI" and "Cloud" — and each project has multiple employees, IMS would first read:
- TechCorp → AI → Employee 1, 2, 3
- Then TechCorp → Cloud → Employee 4, 5
Continuous Path: No Skipping!
In IMS DB, paths must be continuous; you cannot skip segments in the hierarchy. This means that to access a lower-level segment, all its parent segments must be traversed.
If you want data from a lower-level segment (like Employee), IMS must pass through all its parent segments (Company → Project → Employee).
Multiple Paths for Multiple Occurrences
Each occurrence of a segment (like multiple companies or multiple projects within a company) creates multiple possible paths. So, if "TechCorp" and "SoftSolutions" each have several projects and employees, IMS will follow separate paths for each one.
Example:
- TechCorp → Project AI → Employee John
- TechCorp → Project AI → Employee Jane
- TechCorp → Project Cloud → Employee Raj
- SoftSolutions → Project Data → Employee Lily
IMSDB Database path example -