Database Path
Database Path
Path is series of segments that starts from root segment to dependent segment. The dependent segment might not be a child segment and it depends on what segment information user required.
Path is a continuous and can’t skip in between segments. The path should travel all the way through root node to the dependent segment.
The path is described well in the below diagram from A to D1. The access interface processes each record occurrence from top to bottom and from left to right following way:
- The first occurrence of a root segment processed first.
- The first child of a root segment in the defined path is processed before twins of the root segment.
- Twins are processed after a child (if any) down that path.
- Twins are processed in order of occurrence.
- Any child of a twin is processed according to this rule.
- After the child and twins are processed for that one path, the next eligible root segment in the path is processed.
IMSDB Database path example -
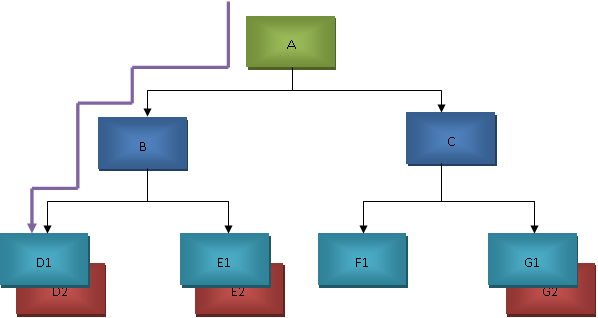
Note! No siblings are processed.